
One of the new features in IDA Pro 5.6 is the possibility to write file loaders using scripts such as IDC or Python.
To illustrate this new feature, we are going to explain how to write a file loader using IDC and then we will write a file loader (in Python) that can extract shell code from malicious PDF files.
Writing a loader script for BIOS images
Before writing file loaders we need to understand the file format in question. For demonstration purposes we chose to write a loader for BIOS image files statisfying these conditions:
- Should be no more than 64kb in size
- Contain the far jump instruction at 0xFFF0
- Contain a date string at 0xFFF5
Each file loader should define at least the two functions: accept_file() and load_file(). The former decides whether the file format is supported and the latter loads the previously accepted file and populates the database.
// Verify the input file format
// li - loader_input_t object. it is positioned at the file start
// n - invocation number. if the loader can handle only one format,
// it should return failure on n != 0
// Returns: if the input file is not recognized
// return 0
// else
// return object with 2 attributes:
// format: description of the file format
// options:1 or ACCEPT_FIRST. it is ok not to set this attribute.
static accept_file(li, n)
{
if ( n )
return 0; // this loader supports only one format
// we support max 64K images
if ( li.size() > 0x10000 )
return 0;
li.seek(-16, SEEK_END);
if ( li.getc() != 0xEA ) // jmp?
return 0;
li.seek(-2, SEEK_END);
// reasonable computer type?
if ( (li.getc() & 0xF0) != 0xF0 )
return 0;
auto buf;
li.seek(-11, SEEK_END);
li.read(&buf, 9);
// 06/03/08
if ( buf[2] != "/" || buf[5] != "/" || buf[8] != "\x00" )
return 0;
// accept the file
return "BIOS Image"; // description of the file format
}
The accept_file() will be called many times by IDA kernel starting with n=0, n=1, n=2, … until it returns zero. This allows you to handle multiple formats present in the same input file.
For example, PE files can be loaded as MS-DOS MZ EXE files or as PE files. The PE file loader plugin does something like this:
if (n == 0)
return "MZ executable";
else if (n == 1)
{
// check if it is a PE file
// ....
return "PE executable";
}
else
return 0;
The li parameter is an instance of loader_input_t described in idc.idc (for IDC) and idaapi.py (for IDAPython). This class allows you to seek and read from the input file.
The load_file() will receive a loader_input_t instance, the format name previously returned by the accept_file() and the loading flags in neflags. This flag can be tested against the NEF_MAN constant to detect whether the user checked the “Manual Load” option while loading the new file.
These are the main responsibilities of load_file():
- Set the processor corresponding to the input file
- Create segments
- Add entry points
- Add fixups
- Create import/export segments
- etc…
// Load the file into the database
// li - loader_input_t object. it is positioned at the file start
// neflags - combination of NEF_... bits describing how to load the file
// probably NEF_MAN is the most interesting flag that can
// be used to select manual loading
// format - description of the file format
// Returns: 1 - means success, 0 - failure
static load_file(li, neflags, format)
{
auto base = 0xF000;
auto start = base << 4;
auto size = li.size();
SetProcessorType("metapc", SETPROC_ALL);
// copy bytes to the database
loadfile(li, 0, base<<4, size);
// create a segment
AddSeg(start, start+size, base, 0, saRelPara, scPub);
// set the entry registers
SetLongPrm(INF_START_IP, size-16);
SetLongPrm(INF_START_CS, base);
return 1;
}
This script (bios_image.idc) is installed with IDA Pro 5.6 in the loaders directory.
Now that we know how to write a simple file loader using a scripting language, let us write a real life file loader that assists us in extracting shellcode from malicious PDF files.
PDF shellcode extractor
The purpose of this article is not to explain how PDF exploits work, however we will explain the general idea as we write the file loader. If you need more information please check Didier Steven’s site and this blog entry, also check Jon Paterson and Dennis Elser blog entry showing how they extracted the shellcode manually and loaded it into IDA for analysis.
In this section we are going to write a very basic shellcode extractor that handles a couple of simple cases.
The first case is when the PDF document contains an embedded JavaScript:
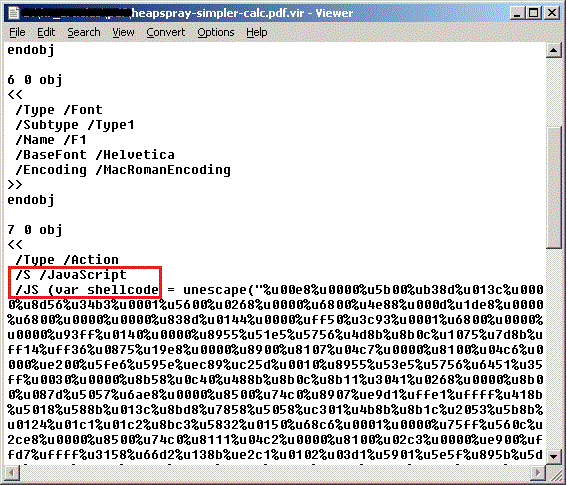
And the second case when an object refers to another object containing the compressed script:
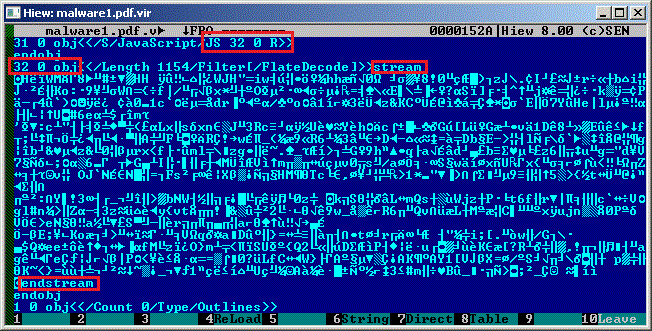
Object 31 refers to object 32 (compressed with DEFLATE algorithm) and contains the actual script that exploits a given vulnerability in the PDF reader.
After taking everything between stream/endstream inside object 32 and passing it to gzip.decompress() we get:
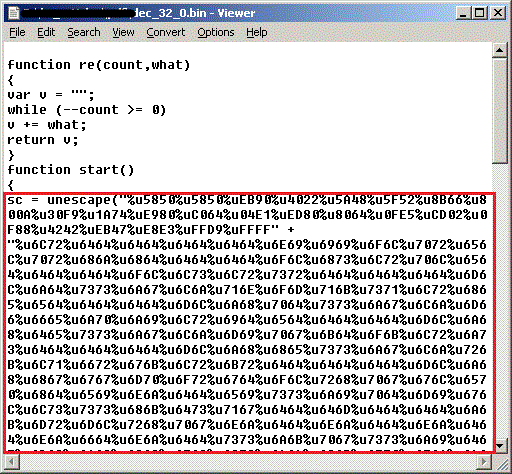
In both cases the shellcode is passed to the unescape() and we can use that as a very basic mechanism to extract the shellcode.
Before writing the code let us summarize what we need to do:
- Find potential JavaScript:
- Scan the PDF document for objects that reference compressed JS streams:
- Find the referencing object
- Find the referred object
- Take the stream and decompress it
- Or scan the PDF document for objects that contains embedded JS and take the JS as-is
- Scan the PDF document for objects that reference compressed JS streams:
- Find all calls to unescape() and extract its parameters. These parameters could be potential shellcode
- Decode the unescape parameter into a byte string
- Create a segment and load the shellcode into the segment
Extracting JS scripts from the PDF
To look for embedded JS scripts we call find_embedded_js() that employs a regular expression:
def find_embedded_js(str):
js = re.finditer('\/S\s*\/JavaScript\s*\/JS \((.+?)>>', str, re.MULTILINE | re.DOTALL)
Once we have a match we remember it without further processing.
To look for compressed JavaScript objects we first call find_js_ref_streams() that also employs a regular expression to locate all objects that refer to another JavaScript object:
def find_js_ref_streams(str):
js_ref_streams = re.finditer('\/S\s*\/JavaScript\/JS (\d+) (\d+) R', str)
We then use the find_obj() to find the body of the refered object (that contains the compressed JavaScript):
def find_obj(str, id, ver):
stream = re.search('%d %d obj(.*?)endobj' % (id, ver), str, re.MULTILINE | re.DOTALL)
if not stream:
return None
return str[stream.start(1):stream.end(1)]
And finally we call decompress_stream() to decompress the referred stream:
def decompress_stream(str):
if str.find('Filter[/FlateDecode]') == -1:
return None
m = re.search('stream\s*(.+?)\s*endstream', str, re.DOTALL | re.MULTILINE)
if not m:
return None
# Decompress and return
return zlib.decompress(m.group(1))
Extracting potential shellcode in the JS scripts
Since this article is for demonstration purposes only, we will assume that the shellcode is always enclosed in the unescape() call. For this we simply convert back the %uXXYY or %XX format strings back to the corresponding byte characters:
def extract_shellcode(lines):
p = 0
shellcode = [] # accumulate shellcode
while True:
p = lines.find('unescape("', p)
if p == -1:
break
e = lines.find(')', p)
if e == -1:
break
expr = lines[p+9:e]
data = []
for i in xrange(0, len(expr)):
if expr[i:i+2] == "%u":
i += 2
data.extend([chr(int(expr[i+2:i+4], 16)), chr(int(expr[i:i+2], 16))])
i += 4
elif expr[i] == "%":
i += 1
data.append(int(expr[i:i+2], 16))
i += 2
# advance the match pos
p += 8
shellcode.append("".join(data))
# That's it
return shellcode
Now we can glue all those helper functions to create one function that returns the shellcode:
def extract_pdf_shellcode(buf):
ret = []
# find all JS stream references
r = find_js_ref_streams(buf)
for id, ver in r:
# extract the JS stream object
obj = find_obj(buf, id, ver)
# decode the stream
stream = decompress_stream(obj)
# extract shell code
scs = extract_shellcode(stream)
i = 0
for sc in scs:
i += 1
ret.append([id, ver, i, sc])
# find all embedded JS
r = find_embedded_js(buf)
if r:
ret.extend(r)
return ret
Writing the file loader
Now that we have all the needed functions to open a PDF and extract all shellcode, let us write a file loader so that we can use IDA to open a malicious PDF file. First we start with the accept_file():
def accept_file(li, n):
# we support only one format per file
if n > 0:
return 0
li.seek(0)
if li.read(5) != '%PDF-':
return 0
buf = read_whole_file(li)
r = extract_pdf_shellcode(buf)
if not r:
return 0
return 'PDF with shellcode'
As you can see, there is nothing special about this function: (1) check PDF file signature (2) check if we found at least one shellcode
And the load_file() will populate all the extracted shellcode into the database:
def load_file(li, neflags, format):
# Select the PC processor module
idaapi.set_processor_type("metapc", SETPROC_ALL|SETPROC_FATAL)
buf = read_whole_file(li)
r = extract_pdf_shellcode(buf)
if not r:
return 0
# Load all shellcode into different segments
start = 0x10000
seg = idaapi.segment_t()
for id, ver, n, sc in r:
size = len(sc)
end = start + size
# Create the segment
seg.startEA = start
seg.endEA = end
seg.bitness = 1 # 32-bit
idaapi.add_segm_ex(seg, "obj_%d_%d_%d" % (id, ver, n), "CODE", 0)
# Copy the bytes
idaapi.mem2base(sc, start, end)
# Mark for analysis
AutoMark(start, AU_CODE)
# Compute next loading address
start = ((end / 0x1000) + 1) * 0x1000
# Select the bochs debugger
LoadDebugger("bochs", 0)
return 1
Testing the script
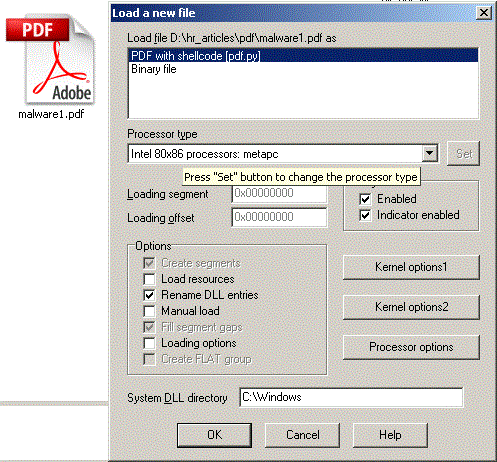
Let us copy the PDF loader script to IDA / loaders directory and open a malicious PDF file:
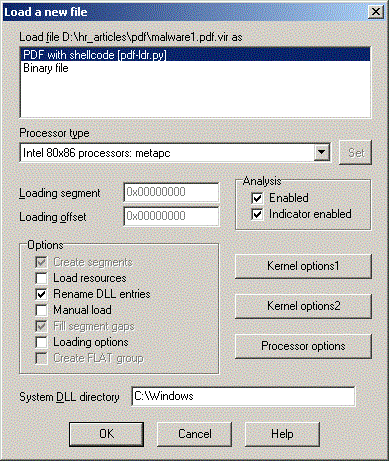
After the file is loaded we can directly see the shellcode:
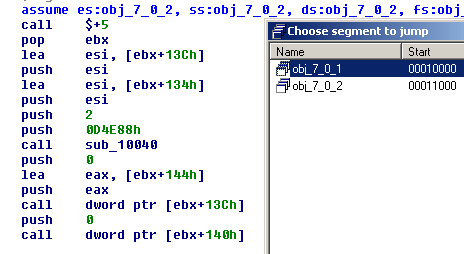
And for the other malware sample, after we load it with IDA:
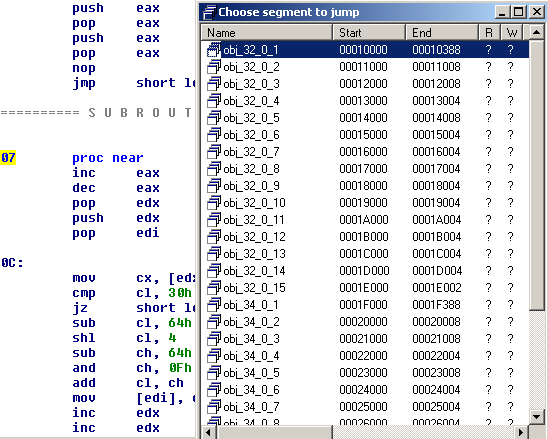
We notice that it contains a decoder that decodes the rest of the shellcode:

To uncover the code we can use the Bochs debugger in the IDB operation mode by selecting the range of code we want to emulate and pressing F9:
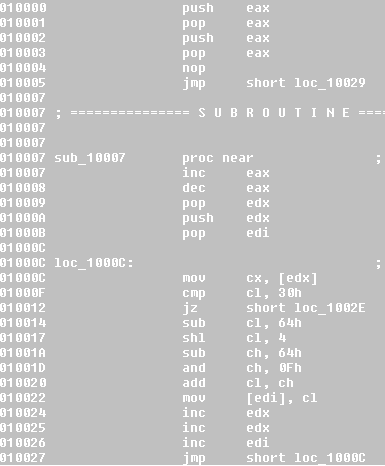
After the decoding is finished we can take a memory snapshot to save the decoded shellcode.
Please download the code from here
Special thanks to Didier Stevens for his free PDF tools and for providing some samples.